Erlang: concurrencia y tolerancia a fallos
Lo que sigue es una transcripción de una clase de la materia Técnicas de programación concurrente de la Facultad de Ingeniería de la U.B.A. La mayoría del contenido —imágenes e ideas— se lo robé a Fred Hebert, particularmente del artículo The Zen of Erlang y del libro Learn you some Erlang for great good. Las slides y el código fuente se pueden encontrar acá.

Introducción
Podemos empezar con un poco de información barata y decir que Erlang es un lenguaje de programación desarrollado por Joe Armstrong y equipo en un laboratorio de Ericsson en los años ‘80. Fue diseñado para cumplir con requerimientos específicos de las aplicaciones de telefonía de la empresa: aplicaciones soft real-time y tolerantes a fallas. La plataforma fue publicada como Open Source en el ‘98 y su diseño, que originalmente apuntaba a un caso de uso “de nicho”, resultó encajar muy bien con las aplicaciones altamente concurrentes que se masificaron en la década siguiente.
Hay varios atributos que lo hacen único o notorio (además de su famosamente extraña sintaxis): es un lenguaje funcional, concurrente, distribuido, observable. Pero lo importante es que la elección de cada uno de esos elementos obedece al objetivo de implementar sistemas tolerantes a fallas. El lenguaje no sigue un modelo teórico específico sino que nació y evolucionó a partir del uso en la industria, lo que explica muchas de sus decisiones de diseño y, en algunos casos, inconsistencias.
Erlang es funcional o, si se prefiere, declarativo, pero no pretende ser puro: para usarlo efectivamente no hace falta saber sobre mónadas o cálculo lambda; y así como, por citar un ejemplo, las variables son inmutables y la memoria de un proceso está aislada de la de los demás, la plataforma provee varias herramientas para romper esas reglas cuando la implementación lo requiere.
Sintaxis
Empecemos con un ejemplo sencillo para tener una idea general de la sintaxis de Erlang:
-module(example1).
-export([list_increase/1]).
%% Incrementar en 1 todos los elementos de la lista.
list_increase(List) ->
list_increase(List, []).
list_increase([N | Rest], Result) ->
list_increase(Rest, [N + 1 | Result]);
list_increase([], Result) ->
lists:reverse(Result).
Por empezar, se declara el nombre de un módulo, example1, y se lista una única función como exportada (pública): list_increase/1, donde el /1 indica la aridad (cantidad de parámetros que recibe). Como está exportada, esta función puede llamarse calificándola con el nombre del módulo que la contiene: example1:list_increase([1, 2, 3]).
Noten que hay una segunda función con el mismo nombre pero diferente aridad, list_instances/2, que realiza el trabajo de construir la lista del resultado.
En Erlang no hay sentencias imperativas como for o while para procesar una colección; la manera básica de iterar es llamando funciones recursivamente. La recursividad es una herramienta muy común pero para casos sencillos como el anterior es más frecuente usar funciones de alto orden:
-module(example2).
-export([list_increase/1]).
%% Incrementar en 1 todos los elementos de la lista.
list_increase(List) ->
lists:map(fun(N) -> N + 1 end, List).
En este caso lists:map/2 recibe una función como parámetro, que aplica a cada elemento de la lista para construir el resultado. Otra opción es usar comprensiones de listas:
-module(example3).
-export([list_increase/1]).
%% Incrementar en 1 todos los elementos de la lista.
list_increase(List) ->
[N + 1 || N <- List].Concurrencia
Erlang implementa el modelo de actores, es decir que los programas consisten en un conjunto de procesos livianos que se ejecutan concurrentemente (y, si se dispone de más de un núcleo, en paralelo), sin estado compartido y comunicándose exclusivamente a través de pasaje de mensajes. Cada proceso tiene un identificador que se usa como la “dirección” para enviarle mensajes; los mensajes se acumulan en un mailbox del que el proceso puede leer asincrónicamente.
A diferencia de otras implementaciones —Akka en la JVM, Actix en Rust—, en el caso de Erlang no se trata de una biblioteca o framework sino que es la propia Virtual Machine la que provee el soporte para este tipo de concurrencia. En efecto, en Erlang no se ejecuta un programa secuencialmente con una función main sino que se inicia el runtime del lenguaje con determinadas aplicaciones —consistiendo cada una de ellas, a su vez, en un conjunto de procesos iniciales.
En la siguiente sesión de shell vemos las primitivas básicas de concurrencia. self/0 devuelve el identificador del proceso actual:
> ParentPid = self().
<0.84.0>
spawn/1 inicia un nuevo proceso y ejecuta en él la función pasada como parámetro:
> spawn(fun() ->
%% Enviar un mensaje al proceso de la shell
ParentPid ! {self(), "hello world!"}
end).
<0.88.0>
Noten que la función es un closure que incluye una copia de la variable ParentPid, asignada en el proceso padre. La expresión receive bloquea la ejecución hasta que el proceso recibe un mensaje que coincida con el patrón indicado, en este caso una tupla de dos elementos {From, Message}:
> receive
{From, Message} ->
%% Imprimir el valor recibido por stdout
io:format("Received: ~p from ~p \n", [Message, From])
end.
Received: hello world! from <0.88.0>
okEjemplo: servidor de cálculos
El tipo más común de proceso es aquel que funciona como un servidor: el que espera a recibir un mensaje (un pedido o request) de otro proceso cliente, hace alguna tarea en base al mensaje —posiblemente modificando su estado interno—, envía una respuesta y vuelve a esperar. Supongamos un servidor que mantiene un número como su estado interno y expone una interfaz para operar sobre ese número:
-module(calc_server).
-export([start/0, add/2, divide/2, get/1]).
start() -> spawn(fun() -> loop(0) end).
El módulo calc_server expone una función start/0 para iniciar el servidor. Esta función crea un proceso y llama por primera vez al loop interno, con 0 como estado inicial. Las funciones add/2 y divide/2 permiten modificar ese número:
add(ServerPid, N) ->
ServerPid ! {add, N},
ok.
divide(ServerPid, N) ->
ServerPid ! {divide, N},
ok.
Noten que esta interfaz es asíncrona: las operaciones se envían al servidor pero no se espera una respuesta, es decir, no se recibe el valor resultante de aplicar la operación sobre el estado del servidor. Para eso se usa otra función, get/1:
get(ServerPid) ->
ServerPid ! {get, self()},
receive
{calc_server_result, Value} ->
Value
after 1000 ->
timeout
end.
Después de enviar el pedido como {get, self()}, el cliente espera hasta un segundo por una respuesta y si no la recibe devuelve el átomo timeout. Por último, la función recursiva loop/1 implementa el proceso servidor:
loop(Acc) ->
NewAcc =
receive
{get, ClientPid} ->
ClientPid ! {calc_server_result, Acc},
Acc;
{add, N} -> Acc + N;
{divide, N} -> Acc / N
end,
loop(NewAcc).Veamos cómo funciona este servidor desde la shell de Erlang:
Eshell V12.0.3 (abort with ^G)
1> c(calc_server).
{ok,calc_server}
2> ServerPid = calc_server:start().
<0.90.0>
3> calc_server:get(ServerPid).
0
4> calc_server:add(ServerPid, 1).
ok
5> calc_server:add(ServerPid, 1).
ok
6> calc_server:get(ServerPid).
2
7> calc_server:divide(ServerPid, 2).
ok
8> calc_server:get(ServerPid).
1.0
9> calc_server:divide(ServerPid, 0).
ok
=ERROR REPORT==== 22-Nov-2021::12:09:14.684986 ===
Error in process <0.90.0> with exit value:
{badarith,[{calc_server,loop,1,[{file,"calc_server.erl"},{line,35}]}]}
10> calc_server:get(ServerPid).
timeout¿Qué pasó al final? Enviamos una operación errónea cuyo manejo no fue previsto en la implementación del servidor. Como resultado el proceso del servidor termina con un error y, cuando intentamos otro pedido usando su identificador, la operación resulta en un timeout, porque el proceso ya no existe.
Más adelante vamos a ver cómo mitigar este tipo de problemas, pero antes hay que hacer algunas observaciones sobre el uso de procesos y el funcionamiento de la Virtual Machine de Erlang.
Los procesos como elemento de diseño
Una parte fundamental del diseño de software es la modularización: organizar el programa en componentes, decidir su granularidad, qué conocimiento debe ser expuesto en las interfaces y cuál encapsulado en las implementaciones. Vimos que Erlang tiene módulos similares a los de Python y otros lenguajes, que cumplen un rol no muy distinto al de las clases de Java, con su interfaz pública y su implementación privada. Pero la separación en procesos es también una forma de modularización y una parte crucial del diseño en Erlang es definir qué lógica y estado son contenidos en cada proceso y qué tipo de mensajes componen su interfaz.
Si miramos el diseño de una aplicación Erlang a alto nivel, podríamos decir que los procesos efectivamente se parecen a objetos, especialmente según la idea original propuesta por Alan Kay en Smalltalk, donde el énfasis se ponía más en el pasaje de mensajes que en las jerarquías de clases. Pero en la práctica, por más livianos que sean los procesos de Erlang, uno no los usaría tan granularmente como a clases de Smalltalk o Java: si implemento una lista enlazada, puede tener sentido una clase Lista y otra Nodo, pero difícilmente sea útil que cada uno de los nodos sea un proceso en Erlang.
Entonces, ¿cómo encontrar la granuralidad adecuada para los procesos? La respuesta surge, otra vez, de la tolerancia a fallos: para separar nuestro programa en procesos tenemos que pensar qué componentes tienen que estar aislados unos de otros: cuáles fallan juntos y aquellos cuya falla no debería afectar al resto. En lugar del encapsular lo que puede cambiar de la programación orientada a objetos, tenemos un encapsular lo que puede crashear.
Virtual Machine
Como dije en la introducción, Erlang no es la única implementación del modelo de actores pero se destaca de otras por estar embebida en el diseño del runtime del lenguaje. La virtual machine de Erlang realiza preemptive scheduling (planificación “preemptiva”), lo que la acerca más a un sistema operativo que a la concurrencia colaborativa de otros lenguajes de programación; esto significa que hay un componente del runtime, el planificador o scheduler, que asegura que todos los procesos tengan un acceso equitativo a los recursos de la CPU. Su funcionamiento puede pensarse así:
- El runtime de Erlang ejecuta un scheduler por cada núcleo de CPU disponible.
- Cada vez que se inicia un proceso, se lo pone en la cola de ejecución de alguno de los schedulers.
- El scheduler toma un proceso de su cola de ejecución y le asigna un número de “reducciones”, algo así como créditos de CPU.
- Cada operación que realiza el proceso (enviar un mensaje, ejecutar una función, abrir un archivo, recolectar la basura en memoria, etc.) consume una cantidad específica de reducciones, que aproxima la cantidad de trabajo de CPU que requiere la tarea.
- Cuando el proceso consume todas sus reducciones, el scheduler interrumpe la ejecución y pasa al siguiente proceso de su cola.
Desde luego que todo ese trabajo realizado por los schedulers tiene un costo y es por eso que Erlang puede ser considerado “lento” en comparación a otros lenguajes, si observamos la ejecución de tareas aisladas. Pero este comportamiento es intencional y es lo que hace a Erlang único en su especie: el objetivo no es hacer el uso más eficiente posible de los recursos sino garantizar su reparto equitativo entre los procesos. Esto es clave en el caso de uso para el que Erlang fue diseñado: sistemas estables, tolerantes a fallas, que degradan elegantemente. En otras palabras, Erlang prioriza latencia sobre rendimiento (throughput): lo más importante no es que las operaciones se ejecuten rápido en promedio sino que la varianza de la latencia se mantenga baja, incluso en situaciones de alta demanda. Lo que el scheduler garantiza es que un proceso que realiza trabajo intensivo no bloquee al resto de los procesos. Esto implica que Erlang suele ser inadecuado para tareas de CPU intensas (criptografía, procesamiento de imágenes) pero ideal para aplicaciones de mucha concurrencia, como servidores web o de chat.
El modelo de memoria sigue un razonamiento parecido: cada proceso tiene su propio espacio de memoria y se ocupa de su garbage collection, consumiendo reducciones de CPU; si bien más costoso que el de un recolector global, este esquema garantiza que los procesos que usan mucha memoria no van a entorpecer el trabajo de los demás. Lo interesante es que, si se diseña y configura bien el programa, muchos procesos van a nacer, realizar su trabajo y morir sin necesidad de llegar a hacer nunca una sola recolección de basura.
Vimos que cada proceso tiene su propio espacio de memoria, aislado del resto, y que toda comunicación se realiza copiando los datos de un heap al otro en la forma de mensajes. Esto elimina los data races y simplifica la implementación de los sistemas y su manejo de errores. Pero dijimos que Erlang es un lenguaje pragmático y por eso complementa ese método con varias herramientas para guardar y compartir estado global de manera eficiente y segura: las ETS (erlang term storage, algo así como un Redis embebido en la plataforma), Mnesia (una base de datos distribuida) y los persistent terms (un espacio global de memoria optimizado para leer datos sin copiarlos al proceso).
Concurrencia robusta
Hablamos mucho de tolerancia a fallas pero todavía no dijimos nada específico sobre el manejo de errores. En Erlang existen elementos similares a los de otros lenguajes (excepciones, señales de terminación) pero más interesantes son las herramientas para el manejo de errores a nivel de procesos. Voy a detenerme en tres:
- Los links vinculan dos procesos de forma que cuando cualquiera de ellos termina en error, se envía una señal de terminación al otro. Conceptualmente, esto indica que ambos procesos están fuertemente relacionados en sus modos de error.
- Las traps cambian la configuración de un link para que, al terminar un proceso en error, se “capture” la señal de terminación hacia el otro proceso y se la convierta en un mensaje en su mailbox.
- Los monitors configuran a un proceso para que reciba un mensaje cuando el otro termina. Es un vínculo unidireccional, sin implicaciones en sus modos de error.
Valiéndonos de estas herramientas, podemos mejorar el ejemplo del calc_server introduciendo otro proceso “supervisor”, encargado de reiniciar el servidor cuando el primero termina en error.
-module(calc_sup).
-export([start_calc_server/0]).
start_calc_server() ->
spawn(fun() -> restarter() end).
restarter() ->
ServerPid = calc_server2:start_link(),
process_flag(trap_exit, true),
receive
{'EXIT', ServerPid, _} ->
io:format("Supervisor: restarting calc_server \n"),
restarter()
end.
El supervisor tiene como única tarea mantener al servidor corriendo; al igual que este, se lo implementa como una función recursiva a la espera de mensajes entrantes. El llamado calc_server2:start_link() inicia el servidor en un nuevo proceso con un link al supervisor, es decir que el supervisor va a recibir señales de terminación cuando el servidor muera, mientras que process_flag(trap_exit, true) es un trap, es decir que esas señales de terminación van a ser convertidas en mensajes. El receive que sigue espera por esos mensajes y vuelve a ejecutar la función, de manera que un nuevo proceso servidor se inicie para reemplazar al que acaba de morir.
Veamos cómo cambia el código del servidor para soportar este nuevo escenario:
-module(calc_server2).
-export([start_link/0, add/1, divide/1, get/0]).
start_link() ->
Pid = spawn_link(fun() -> loop(0) end),
register(calc_server, Pid),
Pid.
La interfaz es muy parecida, solo con cambios en la aridad de las funciones. Como dijimos antes, start_link inicia un proceso servidor enlazado con el proceso que ejecuta la función (en este caso el supervisor); el enlace se crea usando la primitiva spawn_link en vez de spawn. La principal diferencia en esta implementación es el llamado a register(calc_server, Pid); esta instrucción le otorga el nombre global calc_server al nuevo proceso de manera de poder mandarle mensajes usando ese nombre en lugar de su Pid. Esto nos sirve porque el Pid del servidor cambia cada vez que el supervisor crea uno nuevo. En consecuencia, las operaciones del servidor ya no necesitan recibir un Pid sino que usan el nombre global internamente:
add(N) ->
calc_server ! {add, N},
ok.
divide(N) ->
calc_server ! {divide, N},
ok.
get() ->
calc_server ! {get, self()},
receive
{calc_server_result, Value} ->
Value
after 1000 ->
timeout
end.
La implementación de la función loop del servidor es idéntica a la interior. Veamos cómo funcionan estos módulos en otra sesión de shell:
Eshell V12.0.3 (abort with ^G)
1> c(calc_server2).
{ok,calc_server2}
2> c(calc_sup).
{ok,calc_sup}
3> calc_sup:start_calc_server().
<0.95.0>
4> calc_server2:get().
0
5> calc_server2:add(10).
ok
6> calc_server2:divide(10).
ok
7> calc_server2:get().
1.0
8> calc_server2:divide(0).
Supervisor: restarting calc_server
=ERROR REPORT==== 22-Nov-2021::17:34:10.182832 ===
Error in process <0.96.0> with exit value:
{badarith,[{calc_server2,loop,1,[{file,"calc_server2.erl"},{line,44}]}]}
ok
9> calc_server2:get().
0
Noten que, cuando forzamos un error al dividir por cero, hay un crash del servidor, igual que antes, pero esta vez el supervisor lo reemplaza con un nuevo proceso. Al llamar calc_server2:get después del error ya no recibimos un timeout sino la respuesta del nuevo proceso.
OTP y Behaviors
Erlang provee un mecanismo de reuso de código llamado behaviors. Los behaviors son similares a las clases abstractas en programación orientada a objetos, particularmente al patrón template method: permiten implementar casos frecuentes de procesos separando la parte genérica (el módulo del behavior) y la parte específica (un módulo de callbacks). El servidor y el supervisor que vimos antes son ejemplos típicos en los que nos podríamos beneficiar usando una implementación genérica más robusta en vez de reinventar la rueda.
Las distribuciones de Erlang incluyen OTP (Open Telecom Platform), un conjunto de bibliotecas que, más allá de su nombre vintage, componen un framework para construir aplicaciones estándar —aplicaciones que respetan convenciones y funcionan bien con las herramientas del ecosistema de Erlang. OTP contiene varios behaviors, entre ellos:
gen_server(servidor genérico)gen_event(manejo de eventos)gen_statem(máquina de estados)supervisorapplication
Veamos cómo luce nuestro calc_server si lo reescribimos usando gen_server, el servidor de OTP. El behavior resuelve la parte genérica: iniciar un proceso con un nombre global, procesar recursivamente los mensajes entrantes, responder requests asincrónicos o sincrónicos (con un timeout). Nuestro módulo resuelve la parte específica: mantener un número en el estado interno y exponer operaciones para modificarlo.
-module(calc_server3).
-behavior(gen_server).
-export([start_link/0, add/1, divide/1, get/0]).
-export([init/1, handle_cast/2, handle_call/3]).
Con la instruccion -behavior(gen_server). indicamos que este módulo implementa los callbacks que espera gen_server. Para más claridad, separamos las funciones exportadas en dos grupos: una para la interfaz del servidor y la otra para los callbacks del behavior.
start_link() ->
gen_server:start_link({global, calc_server}, ?MODULE, [], []).
add(N) ->
gen_server:cast({global, calc_server}, {add, N}).
divide(N) ->
gen_server:cast({global, calc_server}, {divide, N}).
get() ->
gen_server:call({global, calc_server}, get, _Timeout=1000).
Las operaciones, que antes requerían interactuar explícitamente con procesos, ahora se delegan en llamados al módulo gen_server.
init([]) -> {ok, 0}.
handle_cast({add, N}, Acc) -> {noreply, Acc + N};
handle_cast({divide, N}, Acc) -> {noreply, Acc / N}.
handle_call(get, _From, Acc) -> {reply, Acc, Acc}.La implementación de los callbacks se reduce a manejar los mensajes específicos para las operaciones del nuestro servidor, inicializando, modificando o respondiendo el número interno según sea necesario.
Supervisores
En los ejemplos vimos un escenario rudimentario en el que un proceso (calc_server) realizaba una tarea y otro (calc_sup) se ocupaba de mantenerlo funcionado en presencia de errores. En la generalización de este modelo está el corazón de las aplicaciones de Erlang. Conceptualmente, podemos dividir a los procesos entre trabajdores (workers), los que realizan trabajo y pueden fallar, y supervisores, los que se ocupan de monitorear workers: reiniciarlos o hacer que sus errores tengan consecuencias preestablecidas.
OTP provee un behavior para implementar supervisores. Volviendo al ejemplo de calc_sup, podemos reescribirlo usando este behavior:
-module(calc_sup2).
-behavior(supervisor).
-export([start_link/0]).
-export([init/1]).
start_link() ->
supervisor:start_link(?MODULE, []).
init([]) ->
SupervisorFlags = #{
strategy => one_for_all, %% si falla un worker reiniciar todos
intensity => 5, %% hasta 5 restarts
period => 60 %% cada 60 segundos
},
ChildSpec = [#{
id => calc_server,
start => {calc_server3, start_link, []},
restart => permanent
},
#{
id => calc_loader,
start => {calc_loader, start_link, []},
restart => transient
}],
{ok, {SupervisorFlags, ChildSpec}}.
El supervisor de OTP tiene un solo callback, init/1, que devuelve una tupla de configuración:
- El primer elemento contiene configuración “global” del supervisor: cómo propagar errores entre sus workers (
strategy) y cuál es la frecuencia aceptable de errores (más allá de la cual el propio supervisor deber fallar). - El segundo elemento es una lista de especificaciones de los workers que deben ser supervisados: cómo inicializarlos y qué hacer cuando terminan.
En el ejemplo anterior suponemos que el calc_sup tiene dos workers “hijos”: calc_sup3 y un calc_loader, un proceso de soporte que sirve para inicializar el servidor. La política de restart permanent indica que, cada vez que crashee el servidor, un nuevo proceso debe ser iniciado para reemplazarlo, mientras que el transient del calc_loader indica que este proceso solo debe ser reiniciado en caso de errores (si su ejecución termina normalmente no será reemplazado).
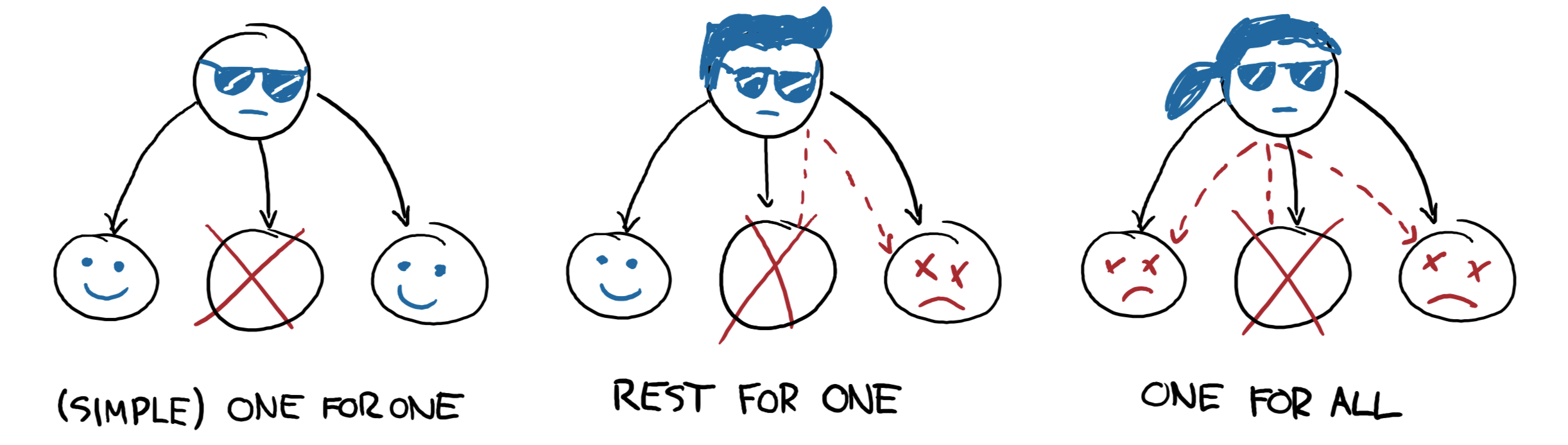
Las estrategias supervisión determinan cómo la terminación de un proceso debe afectar a los demás:
one_for_one: solo se reinicia el worker que murió.rest_for_one: se reinician el worker que murió y todos los que lo siguen en la lista, pero no los anteriores.one_for_all: se reinician todos los workers del supervisor.
En el ejemplo, la estrategia es rest_for_one, lo que significa que la muerte del servidor implica reinicio del servidor y del loader, mientras que si muere el loader solo este se vuelve a iniciar.
¿Cómo se interpreta
esta configuración? Para que nuestra aplicación funcione apropiadamente, queremos que el server esté siempre online (“permanentemente”) y por eso será reiniciado ante cualquier error. Cada vez que lancemos un nuevo servidor, vamos a necesitar cargarle los datos iniciales y por eso el rest_for_one nos garantiza que por cada nuevo servidor se lance un proceso loader. Si el loader crashea antes de terminar correctamente, vamos a reiniciarlo para garantizar que se carguen los datos iniciales, pero esto no requiere también reiniciar el server; como, además, es un worker transient, una vez que termine su carga sin errores, no necesita ser reemplazado.
El Zen de Erlang
Además de procesos workers, los supervisores pueden tener como hijos a otros supervisores, componiendo así jerarquías o “árboles” de supervisión.
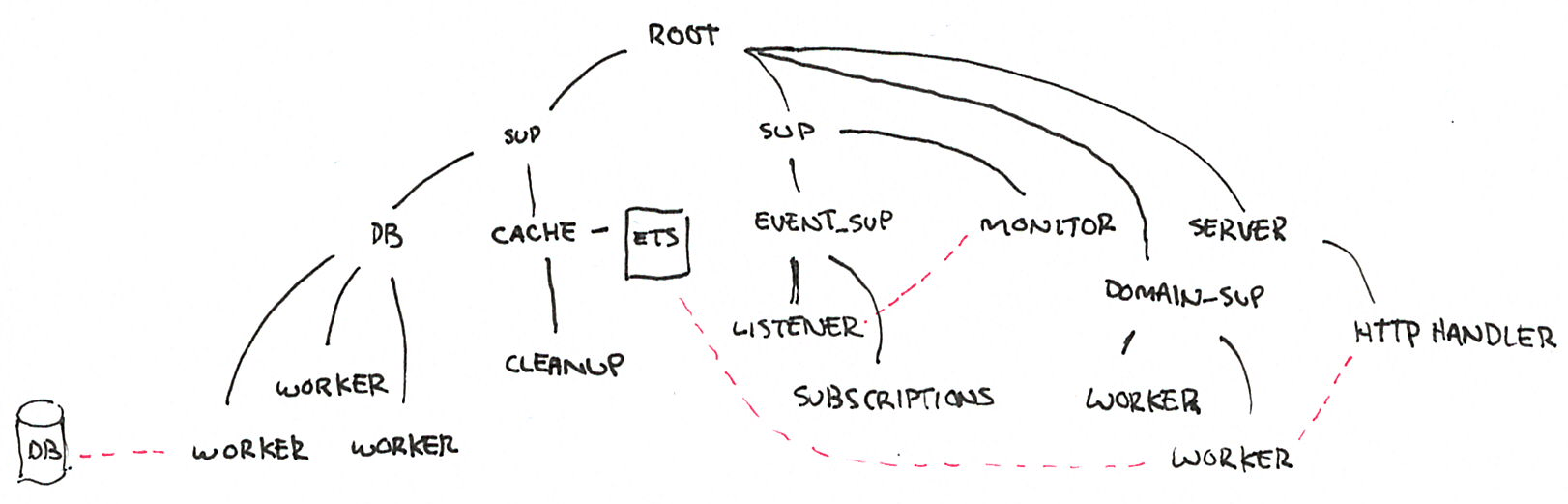
Todas las aplicaciones OTP se estructuran de esta forma (en algunos casos con árboles más planos, en otros más profundos). La manera en que los subsistemas y procesos de una aplicación aparecen en el árbol determinan mucho de su funcionamiento en tiempo de ejecución:
- Los componentes se inicializan en profundidad, de izquierda a derecha. Así podemos saber, en el ejemplo, que los porcesos de base de datos (DB) se van a inicializar antes que el cache, y que ambos se inician antes que el servidor web (server).
- Los errores se propagan en la dirección opuesta a la inicialización: de abajo hacia arriba, derecha a izquierda. Un error en el cache puede afectar a la DB según cómo se configure el supervisor que los contiene a ambos; un error en el servidor web solo afectará a la DB en el caso de que el error se propague hasta la raíz, causando un reinicio de todo el sistema.
- En las hojas del árbol aparecen los workers, los componentes más frágiles, los que esperamos que fallen; en la zona de la raíz están las “garantías” del sistema, el estado conocido al que regresamos cuando los errores no se pueden contener en niveles inferiores.
- Los elementos que escapan al control de la aplicación, como la base de datos, no pueden formar parte de sus “garantías”: como la interacción con la DB se ejecuta a través de la red y la red puede fallar, la disponibilidad de la DB no puede ser una precondición de nuestra aplicación.
Esta manera de estructurar las aplicaciones Erlang encierra el corazón de su filosofía: los errores son inevitables y, en muchos casos, imprevisibles, pero si los controlamos, se convierten en una herramienta. El secreto de los sistemas tolerantes a fallas no es predecir o evitar los errores sino saber recuperarse de ellos, que el sistema pueda volver a un estado consistente. De ahí el lema de Erlang: let it crash (dejalo que se rompa).
La mayoría de los errores son transitorios ![]() , es decir que para recuperarse, como sabe cualquier usuario de Windows, suele ser suficiente con reiniciar. En vez de escribir código defensivo, los programadores Erlang dejan que los procesos mueran y la estructura de supervisión se encarguede lidiar con el problema: reintentar o propagar el error según corresponda. El manejo de errores está en la estructura, en vez de en la lógica del código. Al dejar que se rompa, la implementación del sistema se vuelve más simple, y esa reducción de la complejidad contribuye a su vez a disminuir la cantidad errores.
, es decir que para recuperarse, como sabe cualquier usuario de Windows, suele ser suficiente con reiniciar. En vez de escribir código defensivo, los programadores Erlang dejan que los procesos mueran y la estructura de supervisión se encarguede lidiar con el problema: reintentar o propagar el error según corresponda. El manejo de errores está en la estructura, en vez de en la lógica del código. Al dejar que se rompa, la implementación del sistema se vuelve más simple, y esa reducción de la complejidad contribuye a su vez a disminuir la cantidad errores.

Fuentes
- The Zen of Erlang
- The Hitchhiker’s Guide to Concurrency
- Errors and Processes
- Who Supervises The Supervisors?
- An Open Letter to the Erlang Beginner (or Onlooker)
- How Erlang does scheduling
- Embrace Copying!
- Adopting Erlang - Supervision trees
- Ralph Johnson, Joe Armstrong on the State of OOP
- Processes vs Goroutines
- Erlang Behaviors …and how to behave around them
- Coders At Work - Chapter 6: Joe Armstrong
2021-12-04